
AI assistants have been widely available for a little more than a year, and they already have access to our most private thoughts and business secrets. People ask them about becoming pregnant or terminating or preventing pregnancy, consult them when considering a divorce, seek information about drug addiction, or ask for edits in emails containing proprietary trade secrets. The providers of these AI-powered chat services are keenly aware of the sensitivity of these discussions and take active steps—mainly in the form of encrypting them—to prevent potential snoops from reading other people’s interactions.
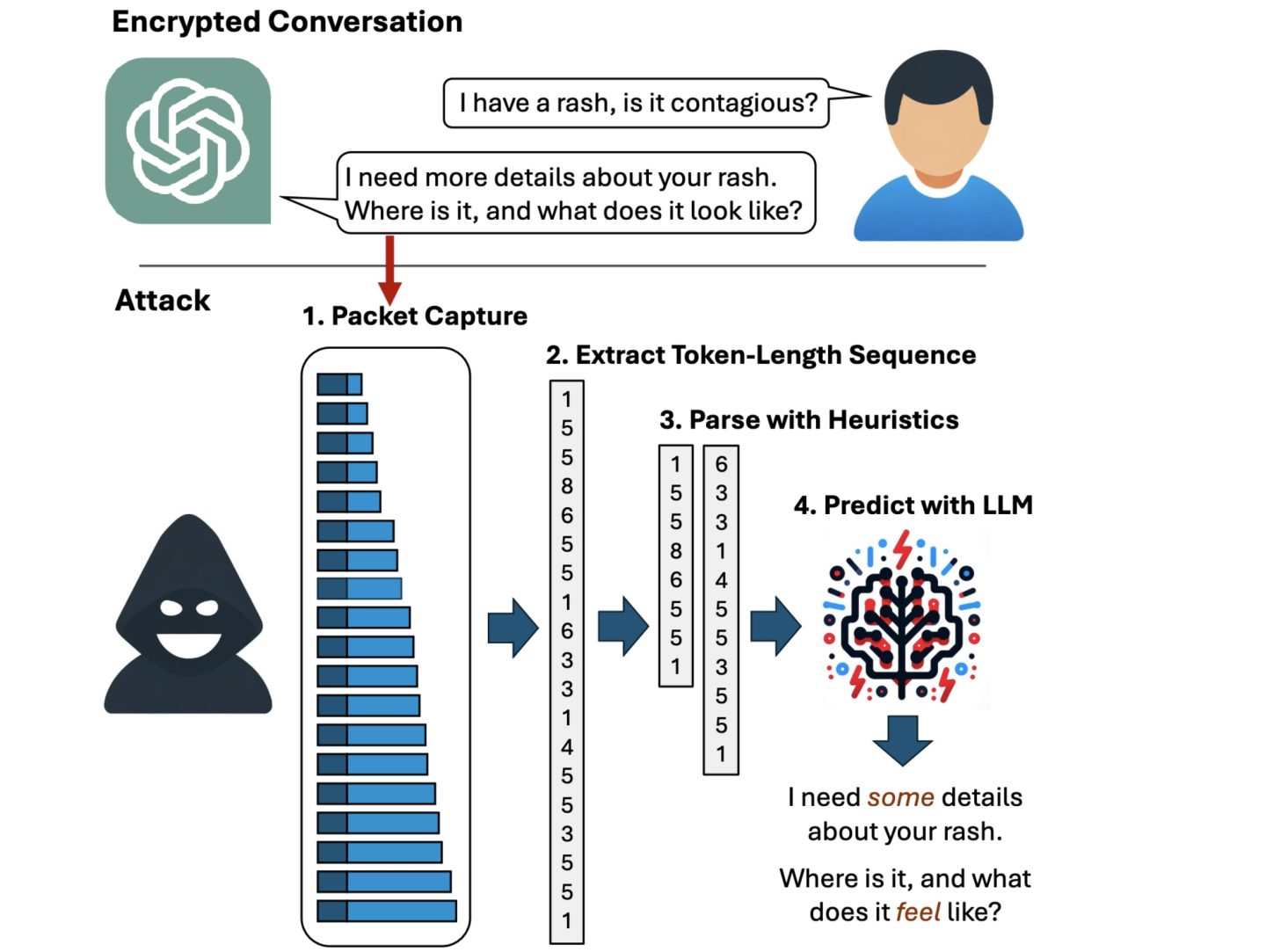
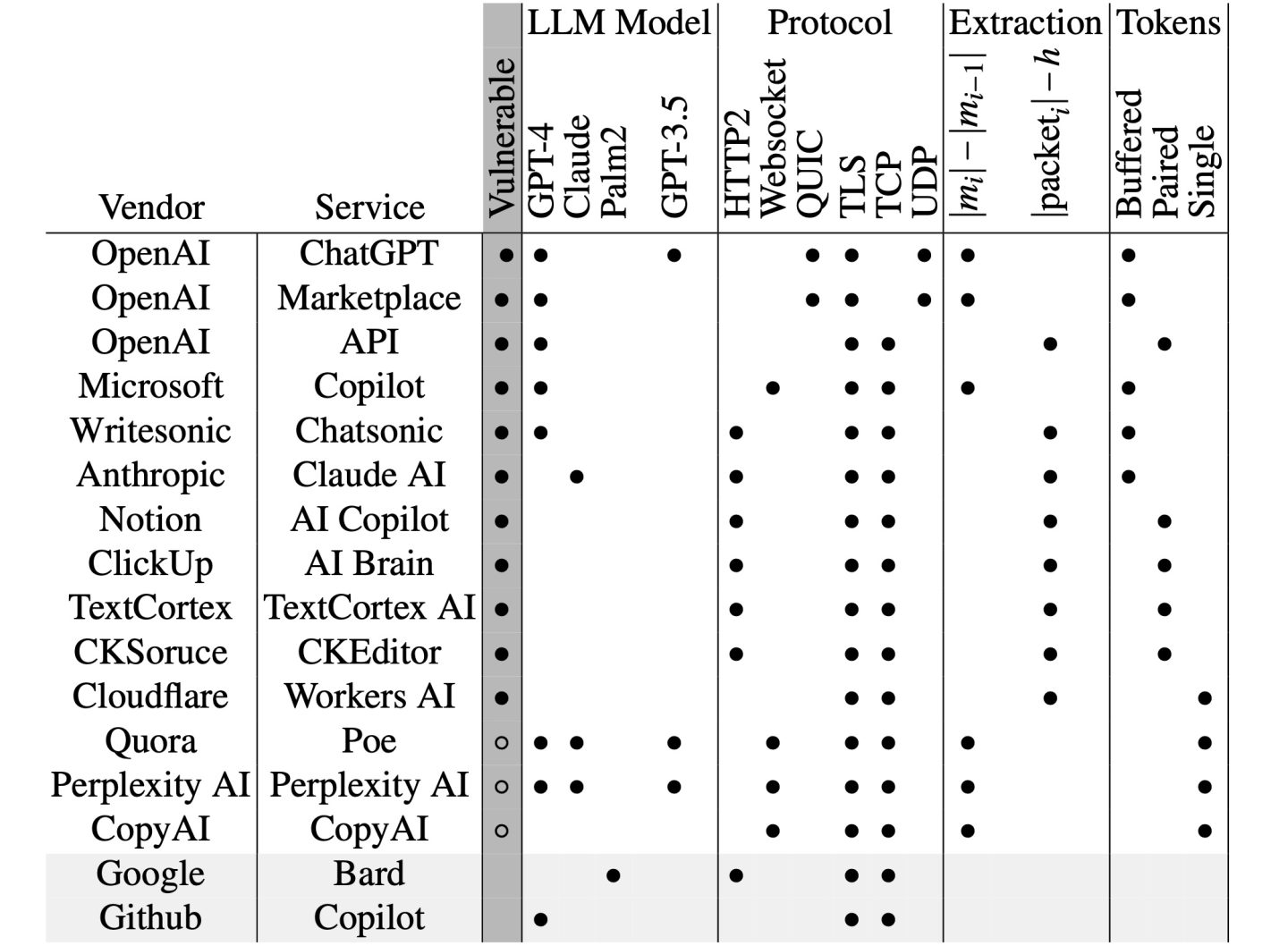
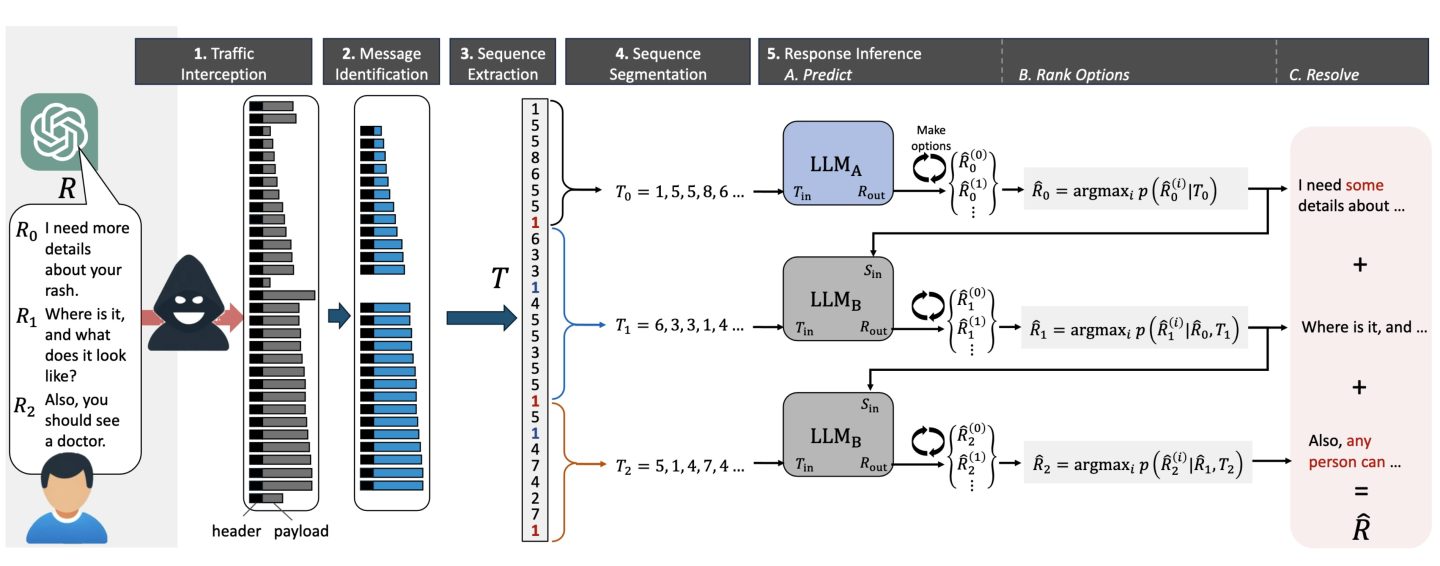
But now, researchers have devised an attack that deciphers AI assistant responses with surprising accuracy. The technique exploits a side channel present in all of the major AI assistants, with the exception of Google Gemini. It then refines the fairly raw results through large language models specially trained for the task. The result: Someone with a passive adversary-in-the-middle position—meaning an adversary who can monitor the data packets passing between an AI assistant and the user—can infer the specific topic of 55 percent of all captured responses, usually with high word accuracy. The attack can deduce responses with perfect word accuracy 29 percent of the time.
Token privacy
“Currently, anybody can read private chats sent from ChatGPT and other services,” Yisroel Mirsky, head of the Offensive AI Research Lab at Ben-Gurion University in Israel, wrote in an email. “This includes malicious actors on the same Wi-Fi or LAN as a client (e.g., same coffee shop), or even a malicious actor on the Internet—anyone who can observe the traffic. The attack is passive and can happen without OpenAI or their client's knowledge. OpenAI encrypts their traffic to prevent these kinds of eavesdropping attacks, but our research shows that the way OpenAI is using encryption is flawed, and thus the content of the messages are exposed.”


 Loading comments...
Loading comments...

Having spotted such a pattern, you then begin analysis. There are only so many tokenization schemes to choose from, so this isn't much more demanding than trying three or four different Secret Squirrel Decoder rings until you find the one that produces English instead of gibberish when tried against your source data.
In some cases, you might be able to simply tell which model's tokenization scheme to use by what the remote IP address is. But even without knowing the remote IP address, if you've been given every word boundary (separate packet) and clues to the content (size of payload in each packet) you can figure out the rest easily enough.
As I see it the bigger picture is to raise awareness to LLM vendors on how they transmit their response over the network. Plus it is another evidence that Transformers are very cool :)
Anticipating this sort of attack, on the other hand, is far from easy. I'm struggling to think of a design or review process that would have exposed this sort of side-channel vulnerability during development.
Despite my multiple misgivings about the way that commercial "AI" products are being developed, I don't think that any of this happened because AI chatbots are being "forced on us" or rushed into production. There were a lot of seemingly-unrelated factors that needed to line up in order for the attack to be viable. This is a novel cryptography problem, not an "AI" problem.
In its simplest distillation, this attack could impact any somewhat-predictable content that's streamed to a user a few chunks at a time. It's well within the realm of plausibility that we're going to discover that there are other non-AI realtime chat and communications apps that have similar vulnerabilities.
The attack itself is somewhat novel and ironic, as it requires the use of a LLM itself.
Web developers are typically not cryptography experts, nor should they need to be (the last thing we want is for individual developers to be implementing their own crypto). One of the selling-points of the modern web stack (HTTPS + TLS) is that neither users nor developers need to worry all that much about transmission security – TLS takes care of that transparently and comprehensively.
If anything, the truly shocking headline here is that LLMs apparently enable a viable side-channel attack against certain niche kinds of TLS traffic.